5. Primary Reading

Once the codes were selected, each document was read in its entirety using Dedoose. Three hundred twenty (320) excerpts were identified. The excerpts were tagged with 506 applications of the 18 codes.

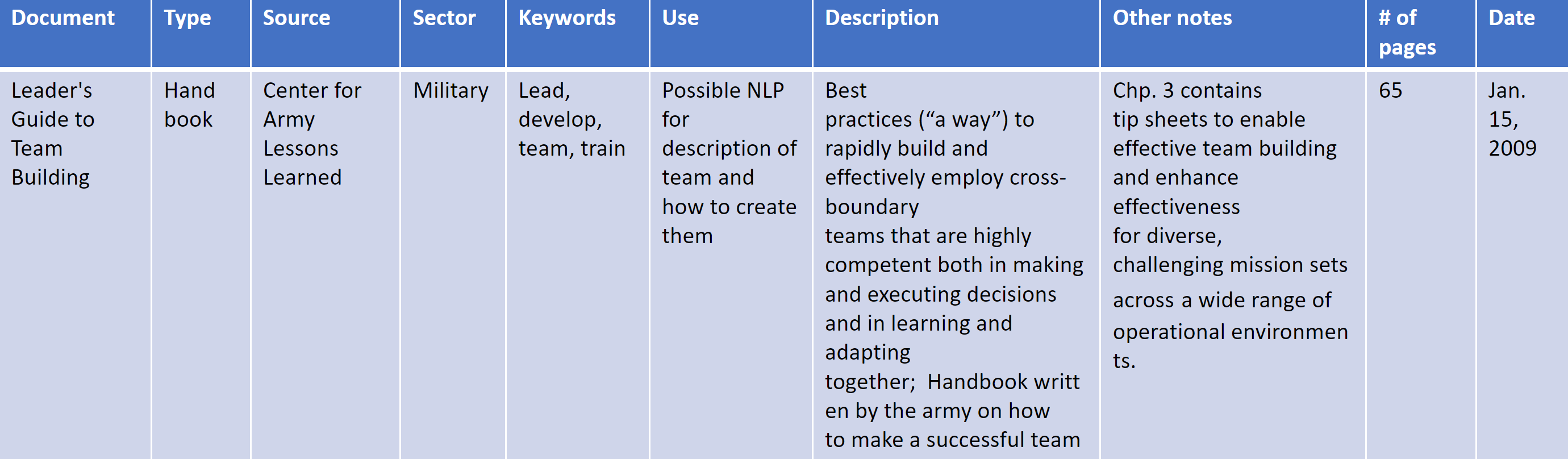 A list of 55 documents from the Army and external sources pertaining to the role of an individual in unit performance were collected. The author, keywords, potential for use in our analyses, detailed document description, date written, and notes were annotated for each document. [1]
A list of 55 documents from the Army and external sources pertaining to the role of an individual in unit performance were collected. The author, keywords, potential for use in our analyses, detailed document description, date written, and notes were annotated for each document. [1]
The research team collectively decided on 10 documents most relevant to our question of interest, as it relates to leadership in the Army and team science, for further analysis. [2]
The 10 documents in the corpus were read a first time to identify emergent themes (i.e., themes about which there were no a priori expectations). A literature review was also conducted to determine possible biases that would influence the documents.
Possible Biases:
Historic Army recruitment tests reinforced institutional bias and maintained segregation. Due to Jim Crow laws, black recruits had not received the same education.
Until August 2014, a row of chairs was placed behind the female platoon at Marine recruit training for recruits who were too exhausted to stand, despite completing boot camp under the same conditions and requirements as their male peers.
“Don’t ask, don’t tell” policy, which barred openly LGBTQIA+ persons from joining the military, was lifted September 20th, 2011. The law claimed, among other things, their presence would “create a risk (…) to unit cohesion.”
After all of the documents were read, the codes were refined. Similarly themed codes were consolidated into a single code, for a final list of 18 major codes to use in the document analysis.

Once the codes were selected, each document was read in its entirety using Dedoose. Three hundred twenty (320) excerpts were identified. The excerpts were tagged with 506 applications of the 18 codes.
Tests were conducted on Dedoose to measure inter-coder reliability. Readers outside of the project reviewed selected excerpts and applied the 18 codes. Their responses were analyzed to see how often the codes they choose matched those of the initial coder.


To begin conducting Natural Language Processing(NLP) on the documents, the corpus was uploaded as text files into R Studio. All of the documents were cleaned by making all of the words lowercase, removing non-letter charters, and removing white space. It was then decided that stop words(i.e. the, and, of) and any word less than four letters should be removed. Last names that were commonly referenced in documents were also removed. Then, all of the documents were legitimatized. Legitimization groups together multiple forms of the same word so that they can be analyzed as a single concept. The cleaning steps can be found on our GitHub here.
The same corpus of documents was analyzed using Natural Language Processing (NLP). To begin the NLP, the corpus was uploaded as text files into R Studio and the documents were cleaned (e.g., all words were coverted to lowercase letters, non-alphabetic characters were removed). All words with fewer than four letters were removed, as words below this limit did not contribute to overall meaning in the documents. The NLP techniques used in this analysis did not take location of a word in a sentence into account, so removing these words had little to no effect on the outcomes. Last names were also removed. Finally, all words were legitimatized. Legitimization groups together multiple forms of the same word so that they can be analyzed as a single concept (e.g., running and runs become run). [3]
Based on the LDA model, codes were matched with the topics to see if the manually labeled documents coincided with the natural language processing.
In the future, it is hope that the corpus would be expanded to include any documents that are similar to the topic but were not originally selected to be included due to constraints. The data collected will be used to inform quantitative models on unit performance.